Derniers Articles
GEO vs SEO : faut-il choisir ou combiner les deux ? Open Knowledge Format : Google pose les bases d’un nouveau standard pour les agents IA Un tribunal allemand juge Google responsable des erreurs de ses AI Overviews La reconversion à l’ère de l’IA générative : les nouvelles compétences attendues des entreprises Google confirme qu’il ignore le fichier llms.txt et clôt le débat L’édition de juin 2026 de Réacteur est en ligne ! SEO technique : comment un agent IA peut auditer et corriger votre site à votre place Sundar Pichai livre un discours aux diplômés de Stanford 2026 : trois règles de vie à retenir Google Business Profile : des numéros WhatsApp ajoutés automatiquement et sans possibilité de suppression SEO + GEO : un nouveau livre blanc pour comprendre les LLM et mieux les influencerLire l'article complet : Mistral frappe fort : nouveau modèle, alliance avec NVIDIA et agent de preuve formelle
Publié le 18/03/2026 à 09:55:23 par Abondance
Mistral frappe fort : nouveau modèle, alliance avec NVIDIA et agent de preuve formelle
En une seule journée, la startup parisienne a dévoilé trois annonces majeures qui confirment son ambition de devenir une brique incontournable de l'infrastructure IA mondiale. Voici ce que ça change concrètement.
Ce qu'il faut retenir :
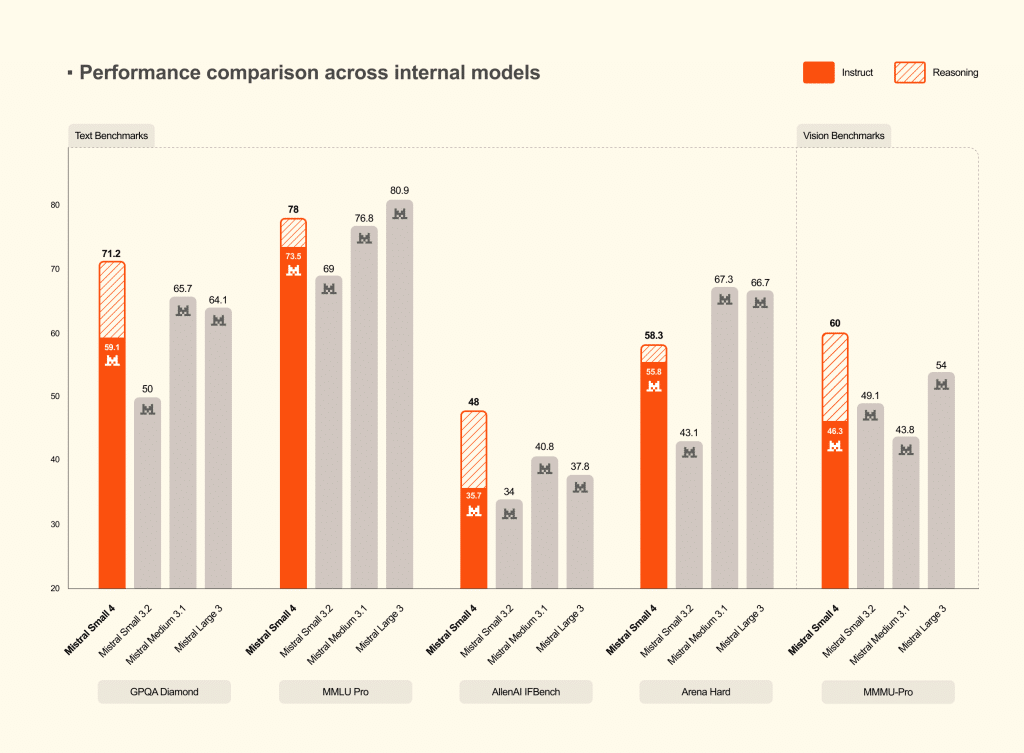
- Mistral Small 4 unifie pour la première fois raisonnement, multimodal et code agentique dans un seul modèle, sous licence Apache 2.0.
- Mistral rejoint la coalition Nemotron de NVIDIA comme membre fondateur, aux côtés de Perplexity, Cursor et Black Forest Labs.
- Leanstral est le premier agent open source capable de générer des preuves formelles de code pour Lean 4, avec un rapport coût/performance revendiqué jusqu'à 15 fois supérieur aux concurrents généralistes.
- Ces trois annonces dessinent un repositionnement stratégique : Mistral ne se présente plus comme une alternative nationale, mais comme un acteur mondial de référence.
Small 4 : un modèle qui remplace trois déploiements
Jusqu'ici, les équipes techniques qui voulaient exploiter les modèles Mistral devaient choisir entre plusieurs outils spécialisés : Magistral pour le raisonnement, Pixtral pour le traitement d'images, Devstral pour le code agentique. Mistral Small 4 met fin à cette fragmentation.
Le modèle repose sur une architecture Mixture of Experts (MoE) : 119 milliards de paramètres au total, mais seulement 6 milliards actifs par requête. Ce fonctionnement permet de conserver une grande capacité globale tout en limitant le coût computationnel à chaque inférence. Par rapport à Mistral Small 3, la startup annonce 40 % de réduction de latence et trois fois plus de requêtes par seconde dans une configuration optimisée pour le débit.
La fenêtre de contexte atteint 256 000 tokens, ce qui permet de traiter des documents longs sans avoir à les découper. Le modèle accepte aussi bien le texte que les images en entrée.
L'ajout le plus notable pour les usages professionnels est le paramètre reasoning_effort. Il permet à l'utilisateur de choisir entre une réponse rapide et légère, équivalente au comportement de Small 3, et une analyse approfondie, étape par étape, comparable aux anciens modèles Magistral. Un seul déploiement couvre donc des besoins qui en nécessitaient trois auparavant.
Sur les benchmarks, Mistral affirme que Small 4 avec raisonnement activé égale ou dépasse GPT-OSS 120B sur trois évaluations testées, tout en produisant des sorties significativement plus courtes. Des sorties plus courtes, c'est moins de latence, moins de coûts d'inférence et une meilleure expérience utilisateur en production.
Le modèle est disponible sur l'API Mistral, Hugging Face, et en tant que conteneur optimisé NVIDIA NIM pour les déploiements sur site. Il est publié sous licence Apache 2.0 et compatible avec les frameworks d'inférence courants : vLLM, llama.cpp, SGLang et Transformers.
La coalition Nemotron : Mistral s'installe à la table des grands
C'est probablement l'annonce la plus stratégique de la journée. Mistral rejoint la coalition Nemotron de NVIDIA comme membre fondateur, aux côtés de Cursor, Perplexity, Black Forest...