Derniers Articles
Les AI Overviews de Google vont enfin débarquer en France Goossips SEO : HTML, Markdown & Sous-répertoires Migration de domaine : Google précise comment utiliser l’outil de « Changement d’adresse » Consultant SEO en agence ou freelance : les 5 actions à mettre en place avant de partir en vacances GEO vs SEO : faut-il choisir ou combiner les deux ? Open Knowledge Format : Google pose les bases d’un nouveau standard pour les agents IA Un tribunal allemand juge Google responsable des erreurs de ses AI Overviews La reconversion à l’ère de l’IA générative : les nouvelles compétences attendues des entreprises Google confirme qu’il ignore le fichier llms.txt et clôt le débat L’édition de juin 2026 de Réacteur est en ligne !Lire l'article complet : JavaScript et SEO, crawl d’un site JS
Publié le 06/06/2023 à 05:35:04 par Neper
JavaScript et SEO, crawl d’un site JS
Il est assez facile de déterminer si un site web a été élaboré à partir d’un framework JavaScript. En revanche, repérer les pages, les sections ou les entités et balises HTML qui sont modifiées dynamiquement via JavaScript s’avère plus complexe. Pour cela, un crawl spécifique est nécessaire. Dans la continuité de notre article sur le JavaScript et SEO, je vous propose de voir comment un crawl avec rendu du JavaScript peut être fait à l’aide de Screaming Frog.
Crawler un site JavaScript avec Screaming Frog
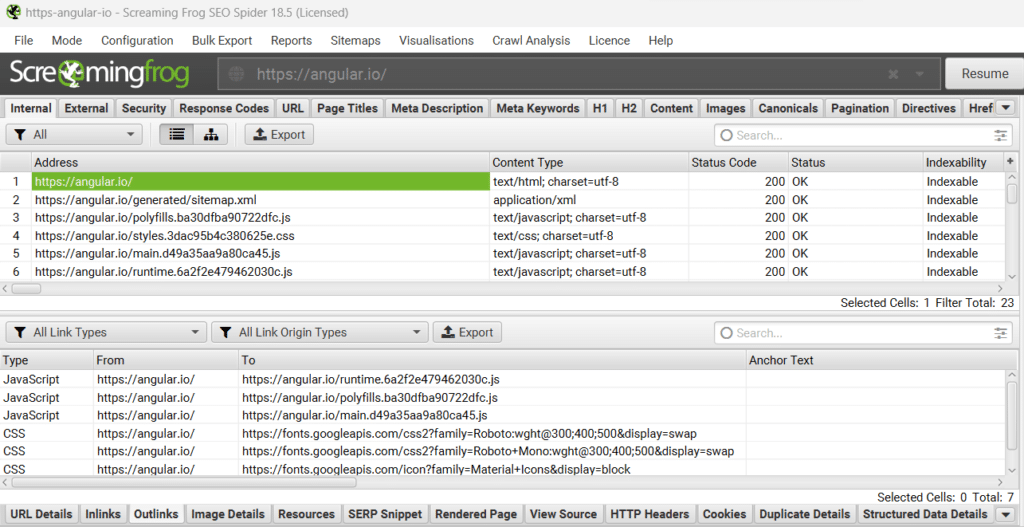
Le mode de rendu d’un crawl par défaut de Screaming Frog est « Text only » (texte uniquement). Dans ce mode, le crawl d’un site CSR (voir notre article), donne des résultats très limités.
Dans l’illustration ci-dessous, on remarque très vite que suite au crawl de la page d’accueil, nous n’avons pas d’autres pages HTML, mais directement des ressources CSS et JS et le sitemap.
Nous savons tous que les liens internes et les liens de navigations sont essentiels pour que les moteurs de recherche puissent découvrir les différentes pages qui composent un site Web. Mais aussi pour avoir un bon aperçu de la structure du site entre autres.
En examinant les liens internes entrants (inlinks) de la page d’accueil de notre site exemple : angular.io, on remarque que celle-ci ne reçoit qu’un seul lien entrant : en provenance du sitemap. Est-ce que cela signifie que les différentes pages du site ne font pas de lien remontant vers la page d’accueil ? Nous y répondrons un peu plus loin dans notre article.
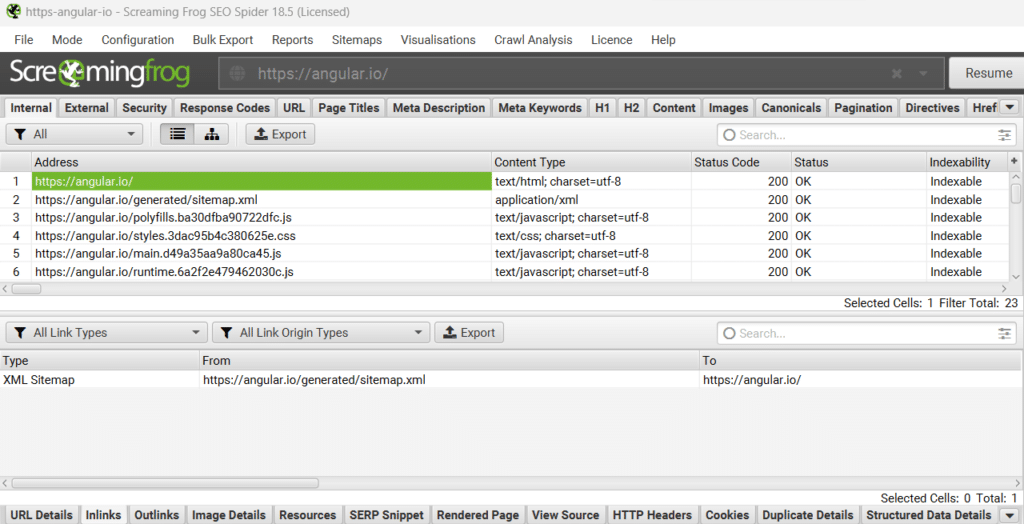
De la même manière, on remarque que la page d’accueil fait des liens internes sortants (outlinks) que vers des ressources JS et CSS, aucun lien HTML avec une ancre cliquable !