Derniers Articles
GEO vs SEO : faut-il choisir ou combiner les deux ? Open Knowledge Format : Google pose les bases d’un nouveau standard pour les agents IA Un tribunal allemand juge Google responsable des erreurs de ses AI Overviews La reconversion à l’ère de l’IA générative : les nouvelles compétences attendues des entreprises Google confirme qu’il ignore le fichier llms.txt et clôt le débat L’édition de juin 2026 de Réacteur est en ligne ! SEO technique : comment un agent IA peut auditer et corriger votre site à votre place Sundar Pichai livre un discours aux diplômés de Stanford 2026 : trois règles de vie à retenir Google Business Profile : des numéros WhatsApp ajoutés automatiquement et sans possibilité de suppression SEO + GEO : un nouveau livre blanc pour comprendre les LLM et mieux les influencerLire l'article complet : Optimiser un site pour les agents IA : les angles morts du GEO
Publié le 29/04/2026 à 11:03:20 par Neper
Optimiser un site pour les agents IA : les angles morts du GEO
Depuis 2024, une part croissante du trafic sortant vers les sites web ne vient plus d’un navigateur humain, ni même d’un crawler classique comme Googlebot.
Elle vient d’agents IA qui récupèrent des URL pour le compte d’un utilisateur. ChatGPT lit une page partagée dans un chat. Perplexity compose sa réponse à partir de plusieurs sources fetchées en temps réel. Claude consulte un article cité dans une conversation. Gemini vérifie un fait au fil d’une requête. Ce trafic n’est pas limité à la documentation développeur, qui a concentré jusqu’ici l’essentiel de l’attention.
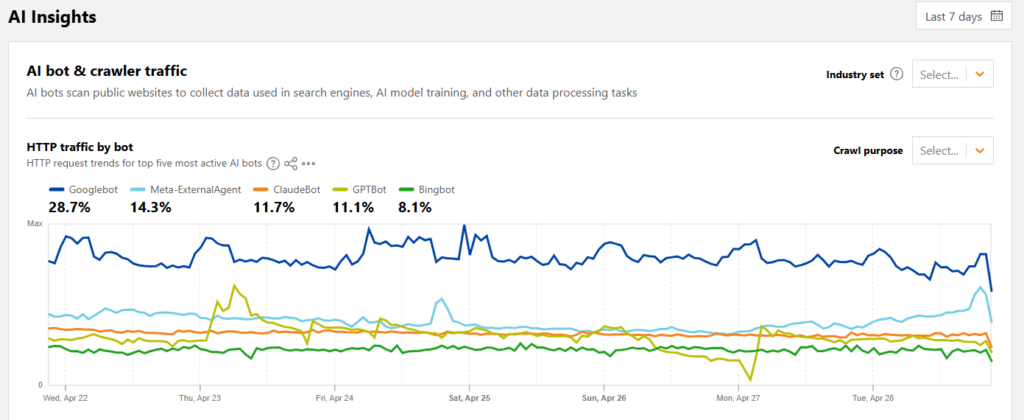
Le trafic des bots IA d’après Cloudflare Radar
N’importe quelle page web, fiche produit, article de presse, page institutionnelle, billet de blog, peut être consommée par ces clients, dans des conditions qui diffèrent de la visite humaine.
Plutôt qu’un nouveau métier ou une nouvelle discipline baptisée d’un acronyme supplémentaire, ce qui se joue est l’extension du périmètre technique du SEO à un nouveau type de « lecteur ». Les contraintes changent, les fondamentaux restent.
Optimiser pour les agents IA, c’est majoritairement des recommandations qui recoupent les prérequis SEO, mais il y’a aussi des choses plus spécifiques : voyons cela plus en détail.
Typologie des agents qui consultent vos pages
Le trafic agent recouvre quatre réalités techniques assez différentes, qu’il faut distinguer avant de parler optimisation.
Les crawlers d’entraînement d’abord, qui passent à l’échelle sur l’ensemble du web. Ils alimentent les corpus d’apprentissage ou les index de retrieval des fournisseurs de LLM. Il s’agit notamment de GPTBot (OpenAI), ClaudeBot (Anthropic), Google-Extended (Google), PerplexityBot, Bytespider (ByteDance). Cloudflare a documenté publiquement une croissance à trois chiffres de ces bots depuis 2024.
Les fetchers temps réel ensuite, déclenchés par une requête utilisateur sans passer par un index préconstruit. Quand un utilisateur colle une URL dans ChatGPT ou Claude, quand Perplexity construit une réponse en direct, la plateforme fetche la page à ce moment-là, souvent avec un user-agent distinct du crawler d’entraînement.
Les assistants agentiques intégrés au navigateur, troisième catégorie. Claude dans Chrome, Gemini dans Chrome, les extensions tierces. Ils consultent des pages au fil de la navigation de l’utilisateur, parfois sans user-agent spécifique.
Les agents de codage enfin, plus spécialisés, comme Claude Code, Cursor ou Cline. Pertinents pour les éditeurs qui publient des URL techniques (API, spécifications, documentation), ils constituent le cas le plus étudié dans la littérature académique récente.
Ce qui change techniquement pour une page web
Quatre contraintes structurelles distinguent ces clients de l’utilisateur humain et même de Googlebot.
La faiblesse du rendu JavaScript d’abord. La majorité des agents fetchent le HTML initial sans exécuter le JS côté client, ou avec un rendu headless très limité. Un contenu injecté via hydratation après chargement est invisible pour ces clients. C’est une contrainte que partage Googlebot depuis longtemps, mais poussée à l’extrême : là où Googlebot tente un rendu différé, un agent de codage ou un fetcher temps réel abandonne immédiatement.
La navigation compressée ensuite. Une étude publiée en 2026 sur les signatures HTTP de neuf agents de codage majeurs montre que le parcours multi-pages s’effondre en une ou deux requêtes. Pas de session, pas de parcours interne valorisé, pas de clic sur un lien de navigation. Chaque URL doit être autosuffisante dans ce qu’elle communique.
La lecture sous contrainte de tokens, troisième différence et probablement la plus structurante. Un token...