Derniers Articles
YouTube dans les LLM : l’étude qui bouscule les certitudes Quand la data nous ment : citations, questions ou titres déclaratifs pour Discover ? Google Search se réinvente : agents IA, box intelligente et temps réel Screaming Frog SEO Spider 24.0 : intégration de l’IA et automatisation accrue Goossips SEO : API d’indexation Comment Bing intègre la sécurité au cœur de la recherche IA L’édition de mai 2026 de Réacteur est en ligne ! Google publie son premier guide officiel pour apparaître dans les résultats IA Google précise que ses règles anti-spam s’appliquent aussi aux réponses IA Google Discover offre des profils enrichis à 54 éditeurs : ce qu’ils en font vraimentLire l'article complet : Quand la data nous ment : citations, questions ou titres déclaratifs pour Discover ?
Publié le 21/05/2026 à 08:15:38 par Abondance
Quand la data nous ment : citations, questions ou titres déclaratifs pour Discover ?
Je suis tombé récemment sur une étude non publique : Parmi d'autres conclusions, les titres avec citation obtiendraient +29 % de visites Discover par rapport aux titres déclaratifs, et les titres sous forme de question seraient les pires.
Deux affirmations testables, que nous avons vérifié. Pas juste en lançant les chiffres dans un modèle, mais en posant les questions qu'un expert pose quand la data semble trop belle.
L'affirmation, et pourquoi elle est tentante
Les titres avec citation obtiennent en moyenne 721 visites Discover. Les titres déclaratifs, 558. Les titres sous forme de question sous-performent les deux, à 425 visites.
C'est net, c'est simple, c'est actionnable : mettez des guillemets, récoltez +29 %. Sauf que Discover, ce n'est pas simple, et la data brute peut raconter une histoire très convaincante... et très incomplète.
Notre terrain de jeu : La data 1492.vision
Pour vérifier, on a analysé les articles éditoriaux ayant reçu au moins un hit Discover sur les 6 derniers mois (nov. 2025 → mai 2026) : 1,7 million d'articles FR et 1,7 million d'articles EN. La métrique n'est pas la visite Discover (inaccessible à un tiers) mais le nombre de captures par article par notre infra : un proxy de la visibilité Discover, sur un volume ~3 000 fois supérieur à celui de l'étude. Nous avons volontairement exclu les ads, les vidéos, les tweets (c'est important comme on le verra plus tard)
On a classé chaque titre en quatre formats : citation en tête (citation longue en début de titre), citation en corps, question, déclaratif (tout le reste). Puis on a analysé à trois niveaux : brut, intra-éditeur, et évolution mensuelle.
Premier résultat : la data semble confirmer
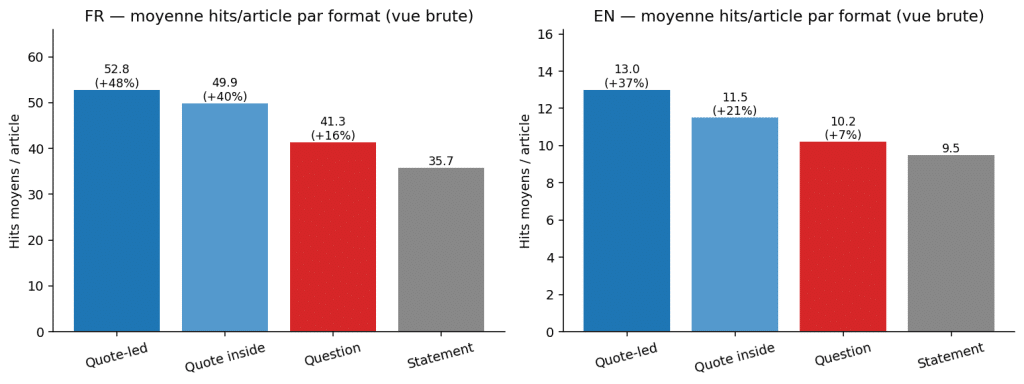
En vue brute, les chiffres sont même supérieurs à l'affirmation d'origine :
| Langue | Citation en tête | Déclaratif | Écart |
|---|---|---|---|
| FR | 52,8 hits/article | 35,7 | +48 % |
| EN | 13,0 | 9,5 | +37 % |
+48 % en FR, +37 % en EN ! La thèse du +29 % serait même sous-estimée.
On pourrait s'arrêter là, publier un thread enthousiaste et passer au sujet suivant. Un LLM, nourri de cette data brute, en tirerait exactement cette conclusion.
Mais c'est là qu'intervient la question que la data seule ne pose pas : et si on n'avait pas mesuré la bonne chose ?
C'est l'expérience, avoir vu des dizaines de cas où un chiffre flatteur cache un biais, qui pousse à creuser.
Le biais que la data cache : on compare des audiences, pas des formats
L'objection est simple : les éditeurs qui utilisent les guillemets ne sont pas les mêmes que ceux qui n'en utilisent pas.
Presse people, PQR, magazines grand public d'un côté.
Pure-players, agences de presse, sites pratiques de l'autre.
Des audiences différentes, des sujets différents, des volumes Discover structurellement différents.
C'est un cas d'école du paradoxe de Simpson : une tendance nette dans les données agrégées (+48 % !) qui s'effondre quand on segmente par groupe. Comparer les moyennes brutes, c'est comparer Paris Match et Le Monde en prétendant mesurer l'effet des...