Derniers Articles
Google met fin au support des FAQ rich results Google teste un nouveau protocole pour distinguer les bons bots des imposteurs SEO agentique : 4 workflows pour transformer vos recommandations en actions avec EdgeSEO Ses clics Google ont été divisés par deux : l’éditeur de Minecraft.fr face à l’impact de l’IA Goossips SEO : Baisse d’indexation Microsoft prépare de nouveaux rapports IA pour Bing Webmaster Tools Google déploie la fonctionnalité « sources préférées » dans toutes les langues Google Search en hausse de 19 % au premier trimestre 2026 : l’IA booste les requêtes à un niveau record Entités et Knowledge Graph : comment construire une présence documentée Google Search et IA : ce que Liz Reid révèle de la transformation en coursLire l'article complet : MUVERA : l’algorithme de Google qui promet une recherche optimisée
Publié le 30/06/2025 à 10:38:36 par Abondance
MUVERA : l’algorithme de Google qui promet une recherche optimisée
Google vient d’annoncer MUVERA, un nouvel algorithme de recherche qui pourrait changer en profondeur la manière dont le moteur traite les requêtes complexes. Son objectif : allier la puissance des modèles multi-vecteurs, capables de comprendre finement le sens des mots et des contextes, à la rapidité des recherches classiques sur vecteur unique. Voici notre décryptage d’une avancée qui pourrait bien remodeler l’univers du SEO et des systèmes de recommandation.
Ce qu'il faut retenir :
- MUVERA transforme la recherche multi-vecteurs en recherche sur vecteur unique, grâce à une technique de Fixed Dimensional Encoding (FDE).
- Des performances largement améliorées, avec jusqu’à 90 % de réduction de la latence par rapport aux anciens systèmes comme PLAID.
- Vers un SEO plus contextuel : l’algorithme privilégie la compréhension sémantique plutôt que le simple matching de mots-clés.
- Une solution adaptée aux grandes échelles, potentiellement exploitable dans la recherche web, les systèmes de recommandation comme YouTube et le traitement du langage naturel.
Comprendre le contexte : pourquoi MUVERA ?
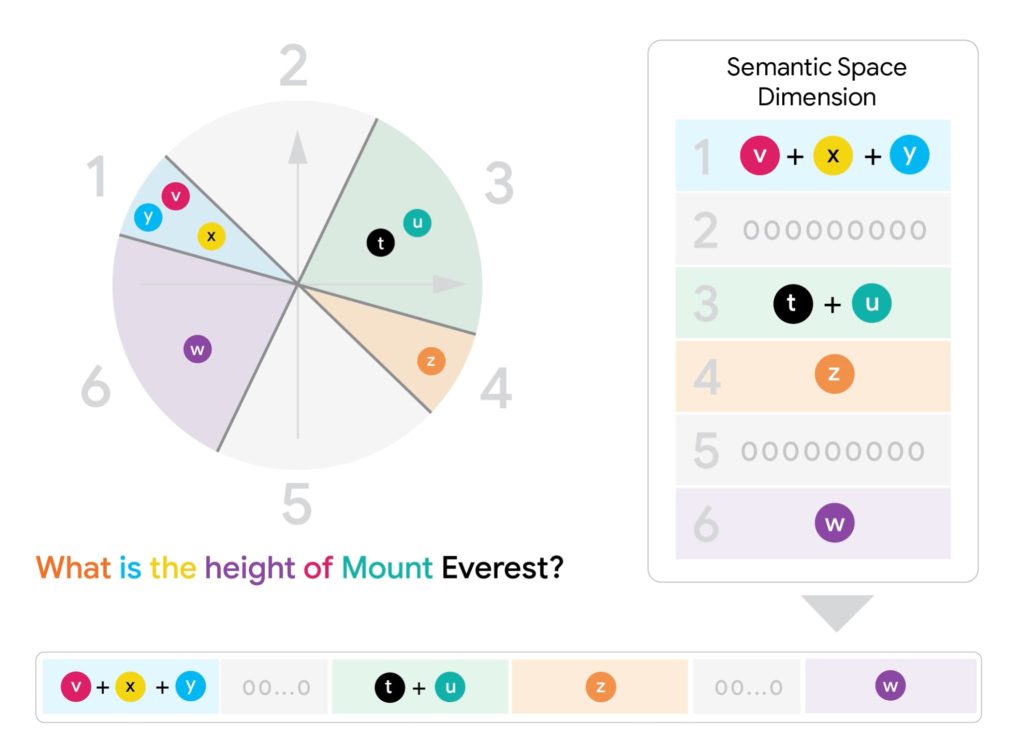
Depuis une dizaine d’années, la recherche d’information (IR) a fait un bond grâce aux modèles dits d’embeddings neuronaux. Ces modèles traduisent textes, images ou vidéos en vecteurs numériques. Leur principe : des contenus sémantiquement proches (par exemple « Le Roi Lear » et « tragédie de Shakespeare ») se retrouvent géographiquement proches dans un espace mathématique. Ainsi, au lieu de simplement compter les mots communs, on évalue la similarité sémantique.
Jusqu’ici, la plupart des systèmes de recherche modernes utilisaient des représentations à vecteur unique. Chaque document ou requête est résumé dans un seul vecteur, ce qui permet une recherche rapide via des techniques comme le Maximum Inner Product Search (MIPS), un algorithme optimisé pour comparer rapidement ces vecteurs.
Mais un problème demeure : ces vecteurs uniques restent parfois trop grossiers pour saisir toute la richesse d’un texte. C’est là qu’interviennent les modèles multi-vecteurs comme ColBERT, qui créent plusieurs vecteurs par document ou requête (souvent un par token). Résultat : une compréhension bien plus fine des relations sémantiques internes. Seul hic : cette finesse a un coût, car comparer plusieurs vecteurs entre eux (via des techniques comme le Chamfer similarity) est extrêmement gourmand en calcul.
MUVERA : la solution signée Google
L’algorithme MUVERA, récemment dévoilé par Google Research, propose un compromis astucieux : conserver la richesse des modèles multi-vecteurs, tout en ramenant la complexité de la recherche au niveau des modèles à vecteur unique.
Son secret : une technique baptisée Fixed Dimensional Encoding (FDE). Plutôt que de manipuler directement tous les vecteurs d’un document ou d’une requête, l’algorithme MUVERA les « condense » en un seul vecteur. Et ce vecteur unique est construit de façon à reproduire au mieux la similarité qu’on obtiendrait si on comparait l’intégralité des vecteurs multi-vecteurs d’origine.
Concrètement, voici comment ça fonctionne sur le plan technique :
- Génération des FDEs
- Chaque token est tout d’abord transformé en vecteur haute dimension.
- L’espace vectoriel est ensuite découpé en zones via des hyperplans aléatoires.
- Pour une requête, on somme les vecteurs tombant dans chaque zone.
- Pour un document, on fait plutôt une moyenne dans chaque zone, pour respecter la nature asymétrique de la similarité Chamfer (qui mesure combien chaque partie de la requête est présente dans le document).
- Recherche rapide via MIPS
Une fois toutes les FDEs générées, la recherche se fait via un simple MIPS sur ces vecteurs condensés. Cela permet d’utiliser l’infrastructure existante ultra-optimisée des moteurs de recherche, sans avoir à comparer tous les sous-vecteurs entre eux. - Re-ranking
Les meilleurs candidats trouvés sont ensuite recalculés avec la véritable Chamfer similarity pour affiner la précision.