Derniers Articles
Comment les IA choisissent leurs sources : retour sur le concours GEO GreenRed HubSpot AEO : un nouvel outil pour booster votre visibilité dans les résultats de recherche IA Google prêt à revoir sa politique anti-parasite SEO pour les éditeurs de presse européens Success Marketing : -30 % sur les billets jusqu’au 22 mai Microsoft Bing nous nous parle de l’évolution de son index Microsoft Bing nous parle de l’évolution de son index Google met fin au support des FAQ rich results Google teste un nouveau protocole pour distinguer les bons bots des imposteurs SEO agentique : 4 workflows pour transformer vos recommandations en actions avec EdgeSEO Ses clics Google ont été divisés par deux : l’éditeur de Minecraft.fr face à l’impact de l’IALire l'article complet : Le chunking : comment rédiger des contenus optimisés pour le GEO et le SEO
Publié le 19/08/2025 à 12:06:18 par Neper
Le chunking : comment rédiger des contenus optimisés pour le GEO et le SEO
Parmi toutes les optimisations spécifiques pour être plus facilement repris dans les réponses des LLMs, le chunking figure en bonne place car un consensus se dégage pour dire que cela fonctionne plutôt bien.
Le “chunking” consiste à veiller à ce que votre contenu soit composé de passages assez courts, et “auto suffisants”.
Cette notion « d’auto suffisance » signifie que si on venait à extraire ce passage du reste du contenu, l’information ou le message que vous vouliez faire passer à cet endroit reste parfaitement compréhensible.
Pourquoi cette optimisation est importante pour la compréhension de votre contenu par les LLMs ?
Ce découpage des morceaux en taille réduite est conçu pour s’adapter au comportement des Transformers lors de l’entrainement et de la génération du modèle. Les Transformers sont une architecture de réseau neuronal qui a permis le développement des LLMs : c’est le T de BERT ou le T dans GPT.
Dans la phase d’entrainement, un transformer analyse chaque contenu en déplaçant une fenêtre qui contient quelques centaines de mots maximum, et qu’il analyse finement pour comprendre la relation entre chaque terme et son contexte (d’où l’appellation de « fenêtre de contexte »). Une fois l’analyse terminée, il déplace sa fenêtre pour travailler sur le morceau suivant. Chaque déplacement permet un recouvrement entre deux fenêtres de contexte de 10 à 20% selon les modèles.
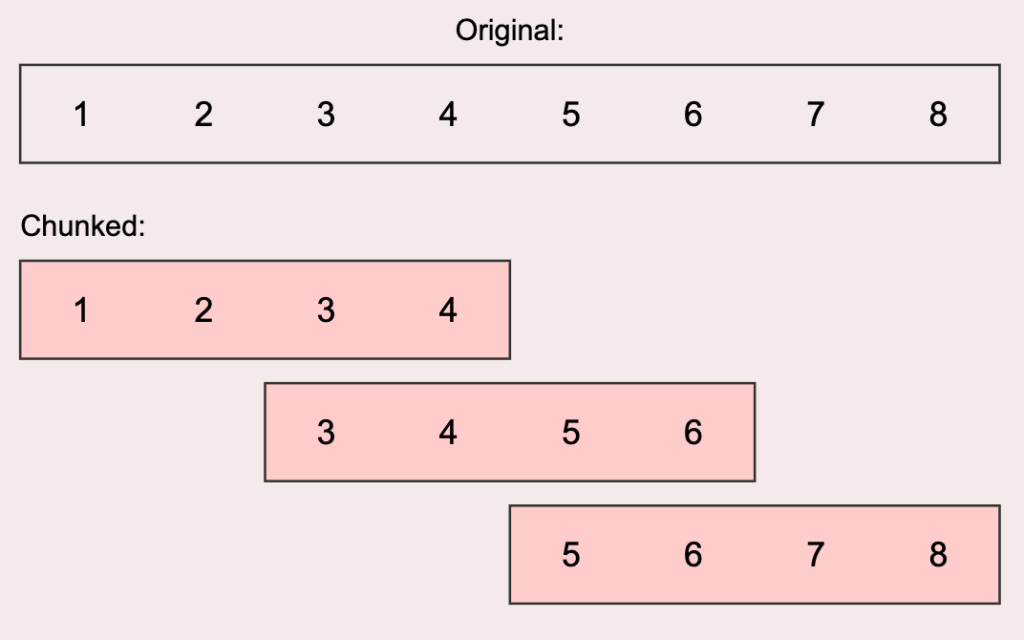
Une illustration du concept de « fenêtre glissante » : cette méthode est employée par le mécanisme d’attention de l’architecture Transformer : source https://amaarora.github.io/posts/2024-07-04%20SWA.html
On retrouve aussi cette logique de fenêtre glissante dans les outils RAG (comme Perplexity ou SearchGPT ou Bing Copilot) lorsque l’outil va chercher des sources sur le net. Pour calculer les vecteurs d’embeddings nécessaires à la génération de sa réponse, la même logique s’applique.
Pourquoi cela marche ?
Quand un utilisateur demande « Comment les plantes font-elles de l’oxygène ? », le système RAG :
- Trouve ce chunk via la similarité sémantique
- Le fournit au LLM qui peut donner une réponse complète
- N’a pas besoin de reconstituer un puzzle d’informations fragmentées
C’est la différence entre donner à quelqu’un un chapitre complet d’un livre vs des pages déchirées au hasard.
Cette approche par chunks cohérents est ce qui permet aux systèmes comme ChatGPT ou Claude de donner des réponses précises à partir de grandes bases de connaissances, sans avoir à traiter des documents entiers de milliers de pages à chaque question !
Les limites imposées par la « complexité quadratique »
Les Transformers (l’architecture derrière GPT, Claude, etc.) utilisent un mécanisme appelé « attention » pour comprendre le texte. Imaginez que pour chaque mot, le modèle doit regarder TOUS les autres mots pour comprendre le contexte. C’est comme si, pour comprendre le mot « pomme » dans une phrase, le modèle devait examiner sa relation avec chaque autre mot.
Le problème, c’est que le nombre d’analyses nécessaires augmente suivant le carré de la longueur de la fenêtre :
- 100 mots = 10,000 analyses de contexte
- 1,000 mots = 1,000,000 analyses de contexte
- 10,000 mots = 100,000,000 analyses de contexte !!
Agrandir la fenêtre produit une explosion combinatoire du temps de calcul et des ressources nécessaires pour le LLM.
La longueur préconisée pour les « chunks » : 200 à 400 tokens
Pour la longueur des « chunks », on raisonne en tokens et non en mots.
Dans tous les outils de traitement du langage, les textes sont convertis en « tokens » (jetons) qui sont des courts ensembles de caractères...