Derniers Articles
Google publie son premier guide officiel pour apparaître dans les résultats IA Google précise que ses règles anti-spam s’appliquent aussi aux réponses IA Google Discover offre des profils enrichis à 54 éditeurs : ce qu’ils en font vraiment Comment les IA choisissent leurs sources : retour sur le concours GEO GreenRed HubSpot AEO : un nouvel outil pour booster votre visibilité dans les résultats de recherche IA Google prêt à revoir sa politique anti-parasite SEO pour les éditeurs de presse européens Success Marketing : -30 % sur les billets jusqu’au 22 mai Microsoft Bing nous nous parle de l’évolution de son index Microsoft Bing nous parle de l’évolution de son index Google met fin au support des FAQ rich resultsLire l'article complet : Évolution de la recherche d’information : du plein texte à la sérendipité
Publié le 11/09/2025 à 06:30:00 par Abondance
Évolution de la recherche d’information : du plein texte à la sérendipité
En trente ans, nous sommes passés d'index rudimentaires à des flux qui devinent nos envies. Pour les médias, les marques et le SEO, ce glissement change tout : l'effort cognitif demandé à l'utilisateur diminue à chaque étape, tandis que la part de l'algorithme augmente. L'infographie associée résume cette trajectoire en quatre phases. Sylvain Deauré, co-fondateur de 1492.vision nous propose le récit complet de cette évolution, avec les implications concrètes.
Pourquoi cette évolution compte
La recherche n'est plus seulement une liste de liens. Elle interprète, répond… puis anticipe.
Cette trajectoire suit trois sauts conceptuels majeurs :
- De « trouver des pages » à « générer des réponses » ;
- D’une logique centrée sur le mot-clé à une logique d'entités et d'intentions ;
- De l'action explicite (« je tape une requête ») à la découverte implicite (« on me propose avant que je demande »).
1. Recherche par index (années 1990)
Cette recherche s’apparente à un index de bibliothèque. On cherche un mot, on obtient des pages où il figure littéralement.
Caractéristiques clés de la recherche par index :
- Une recherche plein texte, sens littéral ;
- L’importance brute de la fréquence des mots ;
- Aucune compréhension d'intention.
Limites de l’approche :
- Littéralisme absolu (synonymes, ambiguïtés comme « jaguar » non gérés) ;
- Spam de mots-clés efficace ;
- Pas de personnalisation ni de hiérarchisation robuste.

On ne peut trouver bien que ce qu'on connaît et qu'on peut nommer.
Quelques repères historiques : W3Catalog (1993), WebCrawler (1994), Lycos (1994), AltaVista (1995). Ces pionniers du web ont popularisé l'indexation full‑text à grande échelle.
2. Recherche intentionnelle (années 2000, Google)
La recherche intentionnelle est comme un bibliothécaire qui comprend ce que vous voulez vraiment. Avec PageRank et la compréhension d'intention, Google bascule la logique : on ne cherche plus seulement des occurrences, on vise des réponses probables.
Caractéristiques de la recherche intentionnelle :
- Réécriture implicite de requêtes ;
- Évaluation de l'autorité via les liens ;
- Premiers indices de « recherche connexe » ;
- Émergence d'une économie du clic où les premiers résultats captent l'attention.
Limites de l’approche :
- L’utilisateur doit encore analyser les « 10 liens bleus » ;
- Pas de synthèse multi‑sources, peu de dialogue ;
- Vulnérabilité aux biais de position et aux manipulations SEO.
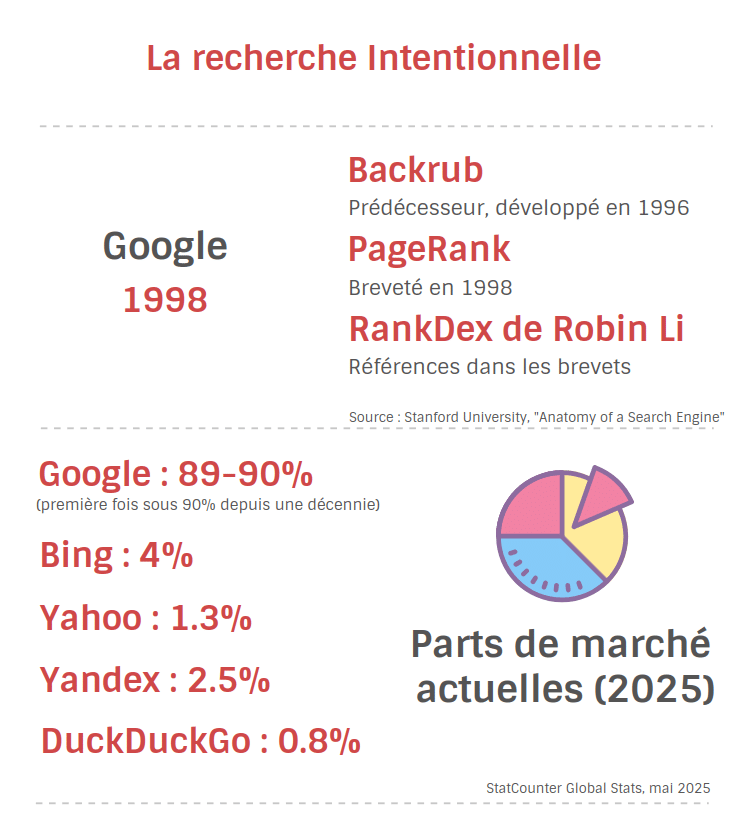
Laisse à l'utilisateur le soin de trouver la réponse dans les 10 liens bleus.
L’impact de la recherche intentionnelle sur le SEO : passage d'une optimisation « mots » à une optimisation « intentions + entités ». Structuration, E‑E‑A‑T, données structurées...