Derniers Articles
Comment Bing intègre la sécurité au cœur de la recherche IA L’édition de mai 2026 de Réacteur est en ligne ! Google publie son premier guide officiel pour apparaître dans les résultats IA Google précise que ses règles anti-spam s’appliquent aussi aux réponses IA Google Discover offre des profils enrichis à 54 éditeurs : ce qu’ils en font vraiment Comment les IA choisissent leurs sources : retour sur le concours GEO GreenRed HubSpot AEO : un nouvel outil pour booster votre visibilité dans les résultats de recherche IA Google prêt à revoir sa politique anti-parasite SEO pour les éditeurs de presse européens Success Marketing : -30 % sur les billets jusqu’au 22 mai Microsoft Bing nous nous parle de l’évolution de son indexLire l'article complet : Cloudflare défie Google avec une refonte majeure de robots.txt : la Content Signals Policy
Publié le 08/10/2025 à 10:43:18 par Neper
Cloudflare défie Google avec une refonte majeure de robots.txt : la Content Signals Policy
Le 24 septembre 2025, Cloudflare a lancé sa Content Signals Policy, une extension du protocole robots.txt qui pourrait redéfinir l’équilibre de pouvoir entre créateurs de contenu et géants de l’IA. Avec 20% du trafic internet mondial sous sa gestion, l’entreprise ne se contente plus de proposer une solution technique : elle lance un défi direct à Google, dont les AI Overviews agrègent le contenu du web sans toujours générer de trafic de retour vers les sources originales. La question n’est plus de savoir si cette initiative est nécessaire – les chiffres parlent d’eux-mêmes : Cloudflare prédit que le trafic bot dépassera le trafic humain d’ici fin 2029. La vraie interrogation porte sur l’application : Google et les autres acteurs majeurs de l’IA joueront-ils le jeu ?
Le protocole robots.txt face à l’ère de l’IA générative : anatomie d’une obsolescence programmée
Le protocole robots.txt (Robots Exclusion Protocol, standardisé par la RFC 9309) a toujours reposé sur un principe fondamental : il indique aux crawlers – ces programmes automatisés qui parcourent le web pour indexer son contenu – quelles parties d’un site peuvent être visitées. Mais il présente une lacune critique dans le contexte actuel : il ne régule que l’accès au contenu, pas son utilisation après collecte.
Cette distinction devient cruciale quand on comprend la différence entre crawling et indexing. Le crawling désigne le processus de découverte et de visite des pages par les moteurs de recherche. L’indexing, lui, correspond au stockage et à l’organisation de ce contenu dans une base de données pour qu’il puisse apparaître dans les résultats de recherche. Un fichier robots.txt peut empêcher le crawling, mais pas l’indexing – une nuance que même les SEO expérimentés oublient parfois.
Dans l’écosystème traditionnel de la recherche, cette limite n’était pas problématique. Les moteurs de recherche indexaient le contenu, mais renvoyaient du trafic via leurs pages de résultats et généraient de l’attribution pour les créateurs. Un contrat implicite existait : les sites acceptaient d’être crawlés en échange de visibilité et de trafic qualifié. Ce modèle économique a soutenu l’économie du web pendant deux décennies.
L’avènement de l’IA générative a rompu cet équilibre. Les LLM (Large Language Models, ou modèles de langage de grande taille) comme GPT, Claude ou Gemini nécessitent des volumes massifs de données pour leur entraînement. Plus critique encore, les fonctionnalités comme les AI Overviews de Google ou les réponses conversationnelles des chatbots utilisent le contenu web en temps réel via RAG (Retrieval-Augmented Generation, une technique qui enrichit les réponses de l’IA avec des données externes récupérées à la volée) sans nécessairement rediriger l’utilisateur vers la source originale. Le résultat ? Un problème classique de free-rider : les entreprises d’IA extraient de la valeur du contenu web sans compenser les créateurs, ni même leur attribuer correctement la paternité de leur travail.
La Content Signals Policy : trois signaux pour reprendre le contrôle
La Content Signals Policy de Cloudflare introduit trois directives distinctes qui étendent le protocole robots.txt au-delà du simple contrôle d’accès. Ces signaux sont intégrés dans le fichier robots.txt sous forme de commentaires (précédés du symbole #), ce qui les rend lisibles par les humains tout en permettant leur interprétation machine via une syntaxe structurée.
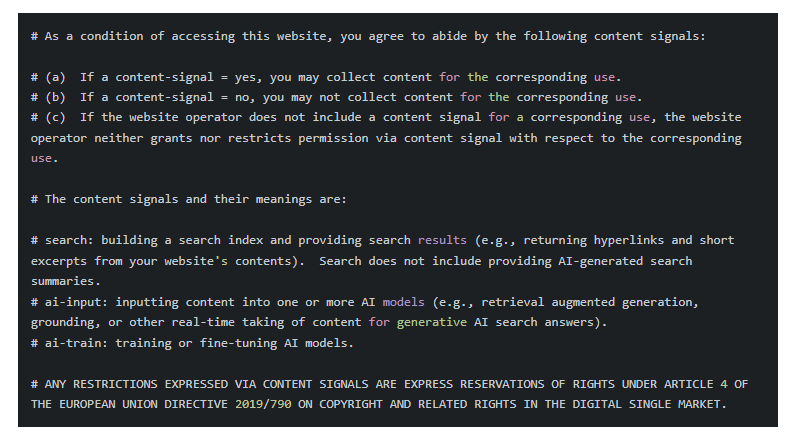
Les trois signaux définis :
- search : autorise la construction d’un index de recherche et l’affichage de liens avec des extraits courts dans les résultats traditionnels. Ce signal couvre l’usage classique des moteurs de recherche où l’utilisateur clique sur un lien pour accéder au contenu source complet.
- ai-input : gouverne l’utilisation du contenu comme input pour des réponses IA générées en...