Derniers Articles
Google publie son premier guide officiel pour apparaître dans les résultats IA Google précise que ses règles anti-spam s’appliquent aussi aux réponses IA Google Discover offre des profils enrichis à 54 éditeurs : ce qu’ils en font vraiment Comment les IA choisissent leurs sources : retour sur le concours GEO GreenRed HubSpot AEO : un nouvel outil pour booster votre visibilité dans les résultats de recherche IA Google prêt à revoir sa politique anti-parasite SEO pour les éditeurs de presse européens Success Marketing : -30 % sur les billets jusqu’au 22 mai Microsoft Bing nous nous parle de l’évolution de son index Microsoft Bing nous parle de l’évolution de son index Google met fin au support des FAQ rich resultsLire l'article complet : Les nouvelles révélations du procès Google vs DOJ sur son algorithme
Publié le 02/10/2025 à 08:03:06 par Neper
Les nouvelles révélations du procès Google vs DOJ sur son algorithme
Le rideau vient de tomber sur l’un des procès technologiques les plus scrutés de la décennie. Le Department of Justice américain contre Google a livré bien plus qu’un verdict juridique : une fenêtre sans précédent sur les rouages intimes de l’algorithme qui gouverne 90% des recherches mondiales.
Si certaines informations avaient déjà été révélées lors des témoignages de fin 2023 (notamment sur Navboost et Glue), les documents de clôture du procès apportent des précisions techniques inédites et révèle officiellement des mécanismes que Google gardait secrets.
Les véritables nouveautés incluent :
- l’architecture détaillée du système DocID et ses signaux multiples,
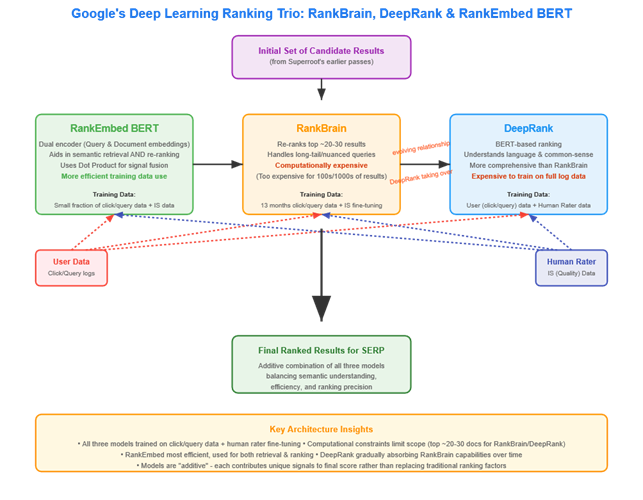
- les précisions sur RankEmbed BERT
- des précisions sur l’utilisation des données Chrome,
- les détails sur l’écosystème IA (GCC, MAGIT, FastSearch),
- et une déclaration sur la prédominance des signaux on-page vs PageRank.
Entre nouvelles révélations sur l’IA et confirmations de systèmes algorithmiques soupçonnés, ces documents transforment notre compréhension du référencement naturel et redéfinissent les priorités stratégiques pour 2025.
L’apprentissage continu : quand chaque interaction sert à entrainer l’algorithme
Selon les documents du procès, « l’apprentissage à partir des user feedbacks des utilisateurs est peut-être la façon centrale dont le classement web s’est amélioré pendant 15 ans. »
Concrètement, chaque recherche génère ce que Google appelle des « exemples d’entraînement ». Le système considère chaque interaction comme « un retour d’information parfaitement clair : ce résultat de recherche est meilleur que celui-là. » Plus fascinant encore, Google peut littéralement « mémoriser » quels résultats sont réellement bons pour des requêtes spécifiques.
Cette approche révèle que l’objectif prioritaire devrait être de créer du contenu que les utilisateurs trouvent réellement utile. Les guidelines de contenu utile de Google ne constituent pas une checklist de facteurs de ranking, mais plutôt des conseils généraux sur ce que les utilisateurs trouvent habituellement pertinent. Les actions des utilisateurs enseignent continuellement à Google quels résultats sont utiles.
Source : Massimiliano Geraci
Cette philosophie, confirmée officiellement dans les documents de clôture, transforme notre compréhension du machine learning appliqué à la recherche. Le machine learning, ou apprentissage automatique, désigne la capacité d’un système informatique à apprendre et s’améliorer automatiquement à partir de données, sans programmation explicite. Ici, nos comportements de recherche alimentent directement l’amélioration algorithmique.
DocID : l’identifiant numérique attribué à chaque page web
Au cœur du système Google se trouve une architecture fascinante : le DocID. Chaque page web indexée reçoit un identifiant unique accompagné d’une constellation de signaux que les ingénieurs appellent « métadonnées » ou « attributs ».

Le DocID était déjà signalé dans le premier papier scientifique de Page et Brin sur le pagerank en 1998
Le DocID, concept hérité des premiers travaux sur PageRank, stocke désormais une richesse d’informations cruciales :
- signaux de popularité mesurés via l’intention utilisateur, les clics, et des systèmes internes comme Navboost et Glue ;
- métriques de qualité incluant l’évaluation...