Derniers Articles
GEO vs SEO : faut-il choisir ou combiner les deux ? Open Knowledge Format : Google pose les bases d’un nouveau standard pour les agents IA Un tribunal allemand juge Google responsable des erreurs de ses AI Overviews La reconversion à l’ère de l’IA générative : les nouvelles compétences attendues des entreprises Google confirme qu’il ignore le fichier llms.txt et clôt le débat L’édition de juin 2026 de Réacteur est en ligne ! SEO technique : comment un agent IA peut auditer et corriger votre site à votre place Sundar Pichai livre un discours aux diplômés de Stanford 2026 : trois règles de vie à retenir Google Business Profile : des numéros WhatsApp ajoutés automatiquement et sans possibilité de suppression SEO + GEO : un nouveau livre blanc pour comprendre les LLM et mieux les influencerLire l'article complet : La recherche vocale de Google devient plus fiable avec le S2R
Publié le 23/10/2025 à 09:15:41 par Abondance
La recherche vocale de Google devient plus fiable avec le S2R
Google remplace la chaîne « parole → texte → recherche » par un modèle qui recherche directement depuis la voix, sans transcription intermédiaire, pour des réponses plus rapides et plus fidèles à l’intention, déjà déployé dans plusieurs langues. Sous le capot, Google relie la requête parlée aux contenus les plus pertinents et laisse son système de classement faire le tri final, tout en s’appuyant sur un jeu de tests ouvert (SVQ) pour évaluer les progrès réels et comparables dans le temps. Explications.
Ce qu'il faut retenir :
- S2R court-circuite l’ASR : la requête parlée est convertie en vecteur sémantique et mise en correspondance directe avec les documents, réduisant les erreurs de transcription.
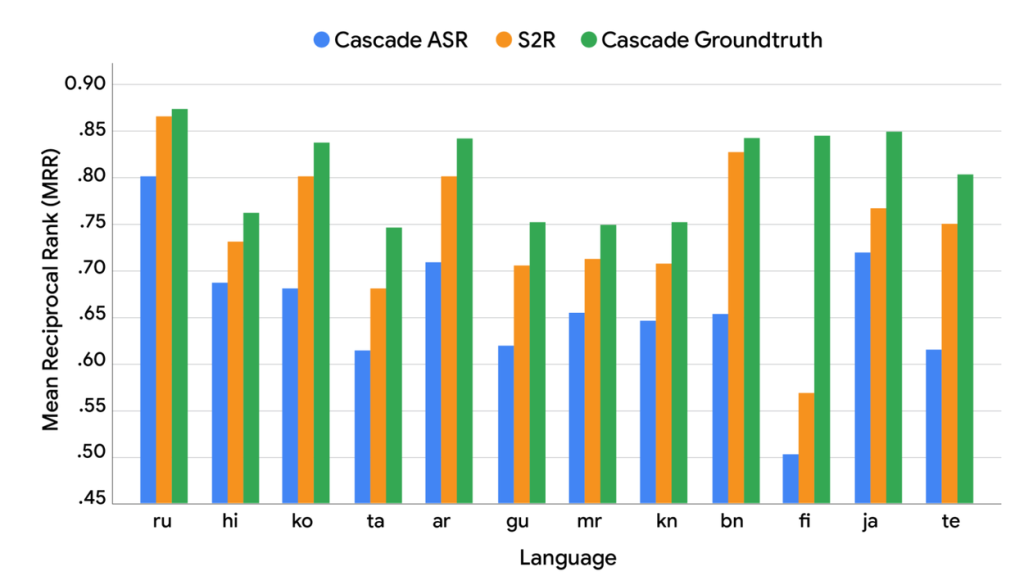
- Les performances dépassent le cascade ASR et flirtent avec le “ground truth” idéal sur MRR, signe d’un saut qualitatif concret en pertinence.
- Le système est live, en plusieurs langues, avec un ranking qui combine similarité sémantique et centaines de signaux de qualité.
- Google publie le dataset SVQ (17 langues, 26 locales) au sein du benchmark MSEB pour faire progresser l’écosystème.
Pourquoi Google change tout maintenant
Jusqu’à maintenant, la chaîne « Cascade ASR » (Automatic Speech Recognition) convertissait d’abord l’audio en texte, puis lançait une recherche classique, mais la moindre erreur (ex. « scream » au lieu de « screen ») déviait l’intention et les résultats, un problème structurel d’erreur de transcription et de perte de contexte. S2R (Speech-to-Retrieval) pose une autre question : non plus « quels mots ont été prononcés ? », mais « quelle information est recherchée ? », ce qui diminue fortement la propagation des erreurs.
Au-delà des exemples, Google a comparé un système réel Cascade ASR avec un « Cascade groundtruth » (transcriptions humaines parfaites) et a observé un écart substantiel en MRR (Mean Reciprocal Rank), montrant que même un ASR parfait ne garantit pas la meilleure pertinence, d’où l’intérêt d’optimiser directement pour l’intention de recherche. Cette observation a motivé l’architecture S2R et l’évaluation dédiée.
Comment fonctionne S2R ?
Le cœur de S2R est un dual-encoder : un encodeur audio transforme la requête vocale en embedding riche, et un encodeur de documents projette les pages dans le même espace sémantique, pour rapprocher les paires audio-document pertinentes et éloigner les autres. L’objectif d’entraînement aligne géométriquement les vecteurs audio avec leurs documents cibles.
En production, l’embedding audio sert à récupérer rapidement des candidats proches dans l’index, puis un étage de ranking orchestre la position finale en combinant la similarité et des centaines de signaux de qualité de Search. Cette intégration conserve la vitesse perçue tout en maximisant la pertinence finale.
Les résultats : mieux que l’ASR, proche du plafond
Sur le dataset SVQ (Simple Voice Questions), S2R surpasse nettement le Cascade ASR et se rapproche du « upper bound » du Cascade Groundtruth en MRR, montrant des gains robustes multi-langues. Google souligne toutefois un petit écart résiduel, laissant un espace d’amélioration future et de recherche.
Point clé révélé par les tests : une baisse de WER (Word Error Rate) ne se traduit pas mécaniquement par une hausse de MRR, car l’impact des erreurs dépend du type d’erreur et de la langue. Optimiser la compréhension d’intention directement depuis l’audio est donc plus pertinent pour la recherche. Cette dissociation WER/MRR justifie l’approche S2R orientée intention.